Fine-tuning with Bumblebee is great but large models such as Mistral 7B demand over 100GB of vRAM to fine tune with full precision. To efficiently fine-tune this on a single RTX 4090 with only 24GB of vRAM, I turned to the open source Python project lit-gpt. This approach enabled me to fine-tune locally, providing several advantages including fast feedback and the ability to keep proprietary data from external providers.
Setup
Although the process is well documented, I decided to outline the steps required for myself just as much as anyone else.
$ git clone https://github.com/Lightning-AI/lit-gpt lit
$ cd lit
$ git checkout bf60124fa72a56436c7d4fecc093c7fc48e84433
$ pip install -r requirements.txt
$ python3 scripts/download.py --repo_id mistralai/Mistral-7B-v0.1
$ python3 scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/mistralai/Mistral-7B-v0.1
Data engineering
Next we need a dataset to fine tune the model with. Unlike the llama 2 example where I fine tuned for dialog I instead wanted to fine tune for capability with Mistral 7B to see what the model was capable of learning. I found a great fine tuned model worth emulating that creates expressions in JSON that mathjson_solver can solve with. The dataset has questions and answers labeled with `instruction` and `output` respectively.
[
{
"input": "",
"instruction": "Create a MathJSON solution to the following:\nPhillip is taking a math test and an English test on Monday. The math test has 40 questions and he gets 75% of them right. The English test has 50 questions and he gets 98% of them right. How many total questions does he get right?",
"output": "\n[\n \"Add\",\n [\n \"Multiply\",\n 40,\n 0.75\n ],\n [\n \"Multiply\",\n 50,\n 0.98\n ]\n]\n "
}
]
With the instruction JSON we simply copy that file into the directory and run a script to prepare the dataset for fine tuning.
$ mkdir -p data/alpaca
$ cd data/alpaca
$ cp ~/somefolder/demo.json .
$ cd ../../
$ python3 scripts/prepare_alpaca.py --checkpoint_dir checkpoints/mistralai/Mistral-7B-v0.1 --data_file_name demo.json
Fine tune Mistral 7B
Once the data is split into test and training sets we are finally ready to fine tune Mistral 7B. It's worth mentioning that we are not fine tuning with full precision because we are tuning with a single RTX 4090 24GB.
$ python3 finetune/lora.py --data_dir data/alpaca --checkpoint_dir checkpoints/mistralai/Mistral-7B-v0.1 --precision bf16-true --quantize bnb.nf4
After the fine tuning process we need to merge the weights.
$ mkdir -p out/lora_merged/Mistral-7B-v0.1
$ python3 scripts/merge_lora.py --checkpoint_dir checkpoints/mistralai/Mistral-7B-v0.1 --lora_path out/lora/alpaca/lit_model_lora_finetuned.pth --out_dir out/lora_merged/Mistral-7B-v0.1
To run this model we first need to copy over a few files from the original model.
$ cd out/lora_merged/Mistral-7B-v0.1
$ cp ~/lit/checkpoints/mistralai/Mistral-7B-v0.1/tokenizer.model .
$ cp ~/lit/checkpoints/mistralai/Mistral-7B-v0.1/*.json .
Evaluate
Before we serve the model with Nx it's important to evaluate it first. This is optional but it does offer a simple way to verify the model has learned something.
$ pip install sentencepiece
$ python3 chat/base.py --checkpoint_dir out/lora_merged/Mistral-7B-v0.1
Serving with Nx
If the model is performing well enough we can pull over the 2 pytorch model bin files and copy the config file so Bumblebee can find it.
$ cd out/lora_merged/Mistral-7B-v0.1
$ cp ~/lit/checkpoints/mistralai/Mistral-7B-v0.1/pytorch_model-00001-of-00002.bin .
$ cp ~/lit/checkpoints/mistralai/Mistral-7B-v0.1/pytorch_model-00002-of-00002.bin .
$ cp lit_config.json config.json
To test this end to end we point Nx at the file system instead of pulling Mistral 7B from hugging face.
def serving() do
mistral = {:local, "/home/toranb/lit/out/lora_merged/Mistral-7B-v0.1"}
{:ok, spec} = Bumblebee.load_spec(mistral, module: Bumblebee.Text.Mistral, architecture: :for_causal_language_modeling)
{:ok, model_info} = Bumblebee.load_model(mistral, spec: spec, backend: {EXLA.Backend, client: :host})
{:ok, tokenizer} = Bumblebee.load_tokenizer(mistral, module: Bumblebee.Text.LlamaTokenizer)
{:ok, generation_config} = Bumblebee.load_generation_config(mistral, spec_module: Bumblebee.Text.Mistral)
generation_config = Bumblebee.configure(generation_config, max_new_tokens: 500)
Bumblebee.Text.generation(model_info, tokenizer, generation_config, defn_options: [compiler: EXLA])
end
Next you can wire this up in your application.ex
def start(_type, _args) do
children = [
{Nx.Serving, serving: serving(), name: ChatServing}
]
end
You can prompt the model from elixir code with Nx.Serving.
Nx.Serving.batched_run(ChatServing, prompt)
With this fine tuned model up and running we can ask it to generate a MathJSON expression.
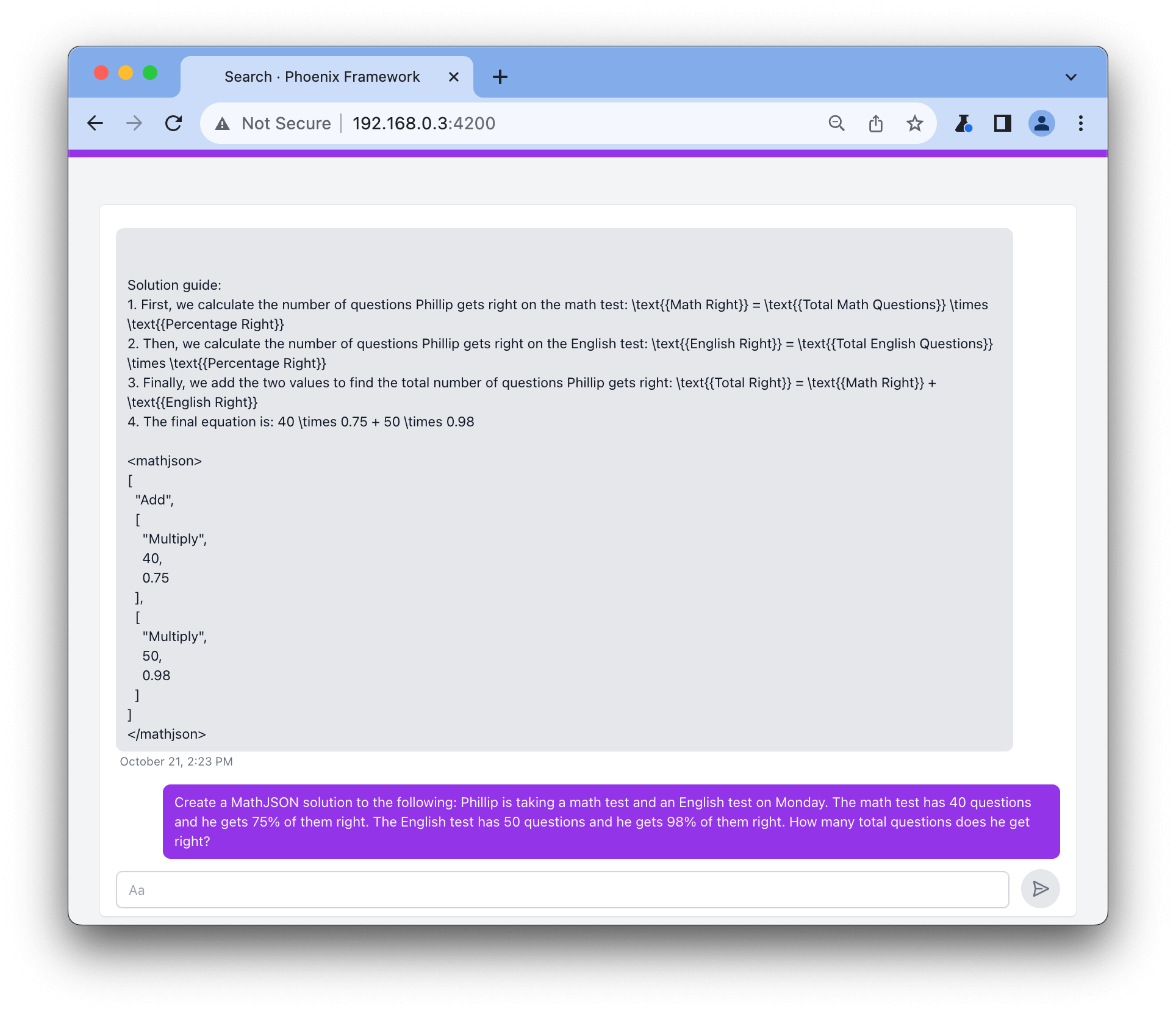
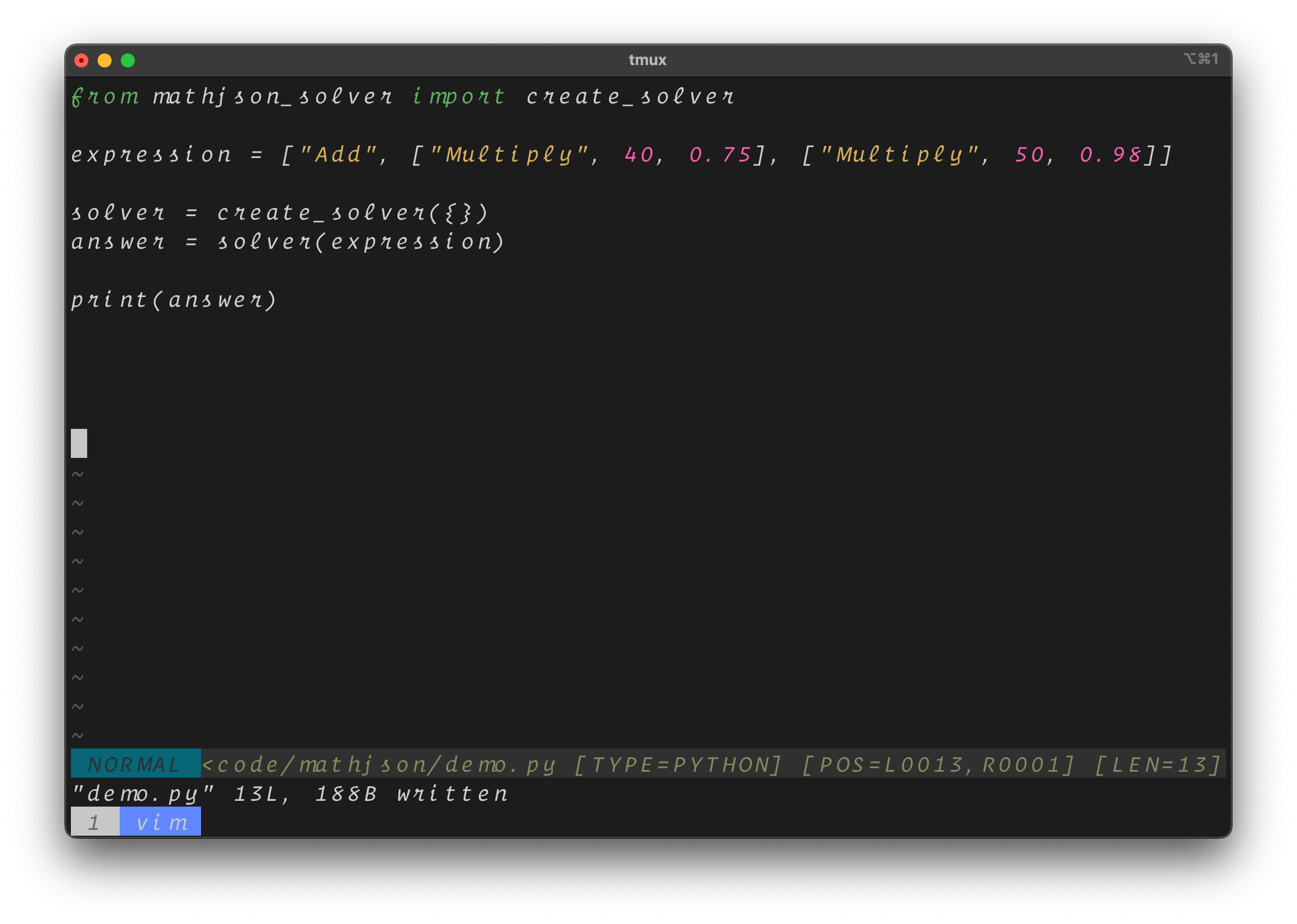
Finally, you can take this output from the model and verify it with help from mathjson_solver.
I want to give a big shout out to Jon Durbin for creating the model that inspired this blog post, the MathJSON dataset and for helping answer a great many questions I had along the way. I also want to thank Sean Moriarity for his work implementing the Mistral 7B model in Bumblebee that made it possible to serve with Nx.
